aws rds에 db를 생성하고, dbeaver로 접속하는 일까지 했었다.
일단 당장 테이블을 만들고 데이타를 넣어보자.

컨트롤 S로 저장하기를 누르면 쿼리가 뜨는데, 따로 쿼리로 치지말고 디비버를 활용해서 저장해주자.
아래 쿼리는 참고용이다.
CREATE TABLE bitcoin.price (
id serial NOT NULL,
usdt float8 NOT NULL,
reg_date timestamp NOT NULL
);
CREATE UNIQUE INDEX price_id_idx ON bitcoin.price (id);
-- Column comments
COMMENT ON COLUMN bitcoin.price.id IS 'id 값';
COMMENT ON COLUMN bitcoin.price.usdt IS 'usdt 가격';
COMMENT ON COLUMN bitcoin.price.reg_date IS '생성 날짜';
이렇게 대충 생성해주면, 시리얼로 만든쪽에 시퀀스가 물리는걸 볼 수 있다.

+ 추가로 reg_date도 따로 값을 넣기 귀찮으니 디폴트에 now()를 넣어 값을 넣어주도록 하자. 변경점을 입력하고 컨트롤 S를 누르면 반영된다.
아래 표를 보고 작성했다. (https://m.blog.naver.com/PostView.naverisHttpsRedirect=true&blogId=kngt13&logNo=80129310667를 참조했다.)
1. ID는 인덱스에서 유니크 값으로 인덱스를 추가해주고 serial은 auto increment 역할을 해준다고 한다.
2. price는 USDT 달라 테더이므로, 소수점이 필수라 플롯 형태를 채용했다.
3. reg_date는 넣은 시간이다. 이는 디폴트에 함수를 입력해 입력 안하도록 할 생각이다.
| bigint | int8 | 8 바이트 부호있는 정수 |
| bigserial | serial8 | 자동 증분 8 바이트 정수 |
| bit [ ( n ) ] | 고정 길이 비트열 | |
| bit varying [ ( n ) ] | varbit | 가변 길이 비트열 |
| boolean | bool | 논리값 (true / false) |
| box | 평면 사각형 | |
| bytea | 이진 데이터 ( "바이트 배열 (byte array)") | |
| character varying [ ( n ) ] | varchar [ ( n ) ] | 가변 길이 문자열 |
| character [ ( n ) ] | char [ ( n ) ] | 고정 길이 문자열 |
| cidr | IPv4 또는 IPv6 네트워크 주소 | |
| circle | 평면 원형 | |
| date | 달력의 날짜 (연월일) | |
| double precision | float8 | double (8 바이트) |
| inet | IPv4 또는 IPv6 호스트 주소 | |
| integer | int , int4 | 4 바이트 부호있는 정수 |
| interval [ fields ] [ ( p ) ] | 시간 간격 | |
| line | 평면의 무한 직선 | |
| lseg lseg | 평면 위의 선분 | |
| macaddr | MAC (Media Access Control) 주소 | |
| money | 화폐 금액 | |
| numeric [ ( p , s ) ] | decimal [ ( p , s ) ] | 정확한 선택 가능한 높은 정밀도 |
| path | 평면의 기하학적 경로 | |
| point | 평면의 기하학 점 | |
| polygon | 평면의 닫힌 기하학적 경로 | |
| real | float4 | 단정 밀도 부동 소수점 (4 바이트) |
| smallint | int2 | 2 바이트 부호있는 정수 |
| serial | serial4 | 자동 증분 4 바이트 정수 |
| text | 가변 길이 문자열 | |
| time [ ( p ) ] [ without time zone ] | 시간 (시간대 없음) | |
| time [ ( p ) ] with time zone | timetz | 시간대가 있는 시간 |
| timestamp [ ( p ) ] [ without time zone ] | 날짜 및 시간 (시간대 없음) | |
| timestamp [ ( p ) ] with time zone | timestamptz | 시간대있는 날짜와 시간 |
| tsquery | 텍스트 검색 문의 | |
| tsvector | 텍스트 검색 문서 | |
| txid_snapshot | 사용자 수준의 트랜잭션 ID 스냅샷 | |
| uuid | 범용 고유 식별자 | |
| xml | XML 데이터 |
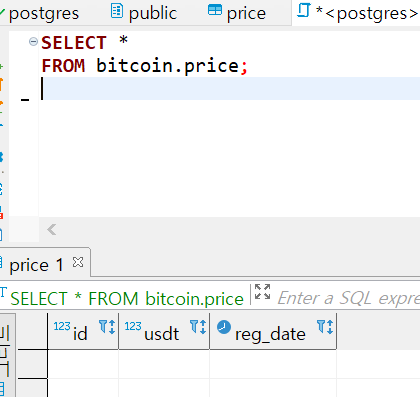
그럼 값을 넣어보자. 계획대로라면 현재 usdt 달러 값만 추가하면 나머지가 잘 들어갈테니...

이제 이 데이타들을 자동으로 넣어줘야한다. 근대 뭔가 잘못된게...정처기 실기는 한달 남았는데, 점점 딴길로 세는것 같다. 걍 책보고 이론 공부해야겠다.
1. 추가로 필요한 데이타 정보를 정하고 외부 api 로 DB 데이타를 넣어주는 스크립트를 작성해야한다.
2. aws 인스턴스 ( 다행이 세팅이 되어있다. )에서 DB로 접근하여 스크립트를 통해 데이타를 넣어준다.
이 두가지 작업을 해야하는데, 책에서 나오는 프로시저까지 접근하기까지 시간이 오래 걸릴 것 같다. 문제는 프로시저가 1장이라는 것이다. 그냥 개인 프로젝트 탭으로 해당 글을 옮기고 얌전히 책공부나 하자.
'IT실습공부 > 개인프로젝트' 카테고리의 다른 글
| 파이썬 비트코인 선물 자전거래 봇 프로토타입 완성 (0) | 2021.11.23 |
|---|---|
| DB 세팅하기 - 1 (0) | 2021.09.13 |
| 코인 정보 db 구성을 구상해보자. (0) | 2020.12.13 |
| aws 서버에 도커를 설치하고 oracle DB 11xe 버전을 구동시켜보자. (0) | 2020.12.12 |
| 개인 사이트의 방문자 정보를 기록하고, 위치정보를 표기해보자 (0) | 2020.12.12 |




댓글